Written by
on
on
기술면접준비
Intro
면접을 위해 따로 공부하는 것 보다는, 열심히 공부한 내용을 바탕으로 면접에서 내 능력을 잘 보여주는 것을 더 선호한다. 면접을 위한 공부가 취업 말고는 무슨 필요가 있겠냐는 생각을 가지고 있었다. 그런데 개발자로 이직하기 위해서 면접을 준비하면서 느낀점은 기술면접의 경우 면접준비 자체가 내 실력을 향상시키는 데에 도움이 되겠다는 생각을 가질 수 있었다. 단편적으로 ‘A는 B입니다.’라고 답변할 수도 있겠지만 한단계씩 더 깊이 물어보는 질문에 답변할 수 있으려면 기술에 대한 더 깊은 지식이 필요하기 때문이다.
면접 준비를 단순히 면접만 준비하기 위한 것이 아니라, 개발자로서 일하기 위해 알고 있어야할 기본 지식들을 잘 공부할 수 있는 기회로서 면접준비 시간을 가져갈 생각이다. 그렇게 되기를 희망하면서 시작한다!
개별 항목 설명에 참고한 책, 사이트
-
기본적인 질문 리스트에 대한 참고 사이트 http://hahahoho5915.tistory.com/16
- 책 :
커니핸 교수의 Hello, Digital World/ 제이펍 출판사하루3분 네트워크 교실/ 영진닷컴
- Overloading과 Overriding에 대한 설명
- Session, Cookie, Cache
- Model - View - Controller 패턴
- Process와 Thread
- Socket
- Stack, Queue, Deque
- Docker
- IaaS, PaaS, SaaS
- Database Index
- [https://ko.wikipedia.org/wiki/%EC%9D%B8%EB%8D%B1%EC%8A%A4(%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4)](https://ko.wikipedia.org/wiki/%EC%9D%B8%EB%8D%B1%EC%8A%A4(%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4))
- https://lalwr.blogspot.kr/2016/02/db-index.html
- http://yagi815.tistory.com/288
- http://parkbosung.tistory.com/11
- 객체지향개발(OOP) 4가지 특성
OOP (객체지향 프로그래밍)
-
OOP란 Object-Oriented-Programming의 약어로써 객체지향 프로그래밍을 의미한다. 데이터를 객체로 취급하여 프로그램에 반영한 것이며, 순차적으로 프로그램이 동작하는 기존의 것들(절차지향 프로그래밍 예: C언어)과는 다르게 객체와 객체의 상호작용을 통해 프로그램이 동작하는 것을 말한다.
- OOP의 특징
- 객체지향 프로그래밍은 코드의 재사용성이 높다.
- 코드의 변경이 용이
- 직관적인 코드분석
- 개발속도 향상
-
상속을 통한 장점 극대화
- Object Object(객체)는 OOP에서 데이터(변수)와 그 데이터에 관련되는 동장(함수), 즉 절차, 방법, 기능을 모두 포함한 개념이다.
Overloading vs Overriding
- Overloading
- 한 클래스 안에서 같은 이름의 메소드를 여러개 정의하는 것
- 매개변수의 타입이 다르거나 개수가 달라야 한다.
- 기본적으로 메소드의 이름이 같기 때문에 매개변수의 타입과 개수가 같다면 오류를 뱉는다. 이름이 같더라도 매개변수의 타입과 개수로 구분된다.
- Overriding
- 상속에서 나온 개념
- 상위 클래스(부모 클래스)의 메소드를 하위 클래스(자식 클래스)에서 재정의
- 이미 존재하는 클래스를 약간만 변경하여 사용하고자 할 경우 새로 클래스를 만드는 것이 아니라 기존 클래스를 상속받아서 기능을 추가하거나 변경하여 사용하는데 이 때 기존 클래스의 기능을 상속 받는 것을 Overriding이라고 한다.
Session, Cookie, Cache
- 개요
- HTTP 프로토콜은 무상태(stateless)다. 이는 HTTP 서버가 클라이언트 요청에 대해 아무것도 기억하지 않아도 된다는 것을 뜻하는 약간의 전문 용어다. 서버는 요청된 페이지를 반환한 후 각 데이터 교환의 모든 기록을 폐기해도 된다.
- 세션과 쿠키의 차이점을 크게 보자면, 쿠키는 상태정보를 클라이언트에 저장하는 방식이고, 세션은 상태정보를 웹 서버에 저장하는 방식이다.
- Cookie
- 1994년에 넷스케이프가
쿠키라는 해결책을 발명했다. - 서버가 웹페이지를 브라우저에 보낼 때, 거기에는 브라우저가 저장하기로 되어 있는 부가적인 텍스트 덩어리들(각각 최대 약 4,000바이트)이 포함 될 수 있다. 각 덩어리를 쿠키라고 하다. 브라우저가 차후에 같은 서버에 요청을 보낼 때, 브라우저는 쿠키를 다시 전송한다. 실제로 서버는 클라이언트의 메모리를 사용하여 클라이언트의 이전 방문에 대한 정보를 기억하는 셈이다.
- 각 쿠키에는 이름이 있으며, 단일 서버에 방문할 때마다 여러개의 쿠키가 저장될 수 있다.
- 쿠키느 프로그램이 아니며, 액티브 콘텐츠가 없다. 쿠키는 완전히 수동적이다.
- 쿠키는 저장됐다가 이후에 다시 전송되는 문자열일 뿐이고, 서버에서 비롯하지 않은 어떤 것도 그 서버로 돌아가지 않는다.
- 쿠키는 자신이 유래한 도메인으로만 전송된다.
- 쿠키는 유효기간이 있어서 그 이후에는 브라우저에 의해 삭제된다. 브라우저가 실제로 쿠키를 받아들이거나 반환해야 한다는 요구 사항은 없다.
- 1994년에 넷스케이프가
- Session
- 쿠키는 모든 정보를 브라우저에 저장하기 때문에 보안상의 이슈가 있다.
- 반면에 세션은 사용자를 확인 할 수 있는 식별자만 쿠키의 형태로 브라우저에 저장하고, 그와 관련된 데이터는 서버의 데이터베이스에 저장하는 형태다.
- session-id를 탈취당할 우려가 있기 때문에 보안적인 문제가 여전히 남아있다.
- Cache
- Cache란 웹페이지 Resource파일들(오디오, 비디오, 이미지 등)의 임시 저장소로 브라우저에 저장된다.
- 다음에 같은 웹페이지(혹은 웹사이트)로 접속시 이미 리소스 파일들이 브라우저에 저장되어 있기 때문에, 페이지 로딩 속도를 개선해 준다.
- Session과 Cookie의 비교
- 쿠키는 만료시간이 있지만 파일로 저장되기 때문에 브라우저를 종료해도 계속해서 정보가 남아있을 수 있다. 또한 만료기간을 넉넉하게 잡아두면 쿠기삭제를 할 때 까지 유지될 수도 있다.
- 반면에 세션도 만료시간을 정할 수 있지만 브라우저가 종료되면 만료시간에 상관 없이 삭제된다.
- 쿠키에 정봑 있기 때문에는 서버에 요청시 속도가 빠르고 세션은 정보가 서버에 있기 때문에 처리가 요구되어 비교적 느린 속도를 낸다.
MVC 패턴
- Model - View - Controller 는 소프트웨어 공학에서 사용되는 소프트웨어 디자인 패턴이다.
- 이 패턴을 성공적으로 사용하면, 사용자 인터페이스로부터 비즈니스 로직을 분리하여 애플리케이션의 시각적 요소나 그 이면에서 실행되는 비즈니스 로직을 서로 영향 없이 쉽게 고칠 수 있는 애플리케이션을 만들 수 있다.
- MVC에서 모델은 애플리케이션의 정보(데이터)를 나타내며, 뷰는 텍스트, 체크박스 항목 등과 같은 사용자의 인터페이스 요소를 나타내고, 컨트롤러는 데이터와 비즈니스 로직 사이의 상호동작을 관리한다.
Thread와 Process
- Process
- 운영체제에서 실행중인 하나의 프로그램 (하나 이상의 쓰레드를 포함한다.)
- Thread
- 프로세스 내에서 동시에 실행되는 독립적인 실행 단위
- 차이점
- 프로세스는 운영체제로부터 자원을 할당받는 작업의 단위이고 스레드는 프로세스가 할당받은 자원을 이용하는 실행의 단위다. 프로세스는 실행될 때 운영체제로부터 프로세서를 할당받고, 운영되기 위해 필요한 주소 공간, 메모리 등 자원을 할당받는다. 스레드는 한 프로세스 내에서 동작되는 여러 실행의 흐름으로, 프로세스 내의 주소 공간이나 자원들을 같은 프로세스 내에 스레드끼리 공유하면서 실행된다.
- 여러 프로세스(멀티 프로세스)로 할 수 있는 작업을 하나의 프로세스에서 스레드로 나눠서 하는 이유
- 결론적으로는 운영체제는 시스템 작업을 효율적으로 관리하기 위한 것이므로 이 목적을 달성하기 위해 스레드를 사용하는 것
- 프로세스로 실행되는 작업을 멀티 스레드로 실행할 경우, 프로세스를 생성하여 자원을 할당하는 시스템 콜이 줄어들어 자원을 효율적으로 관리할 수 있다. 뿐만 아니라 프로세스 간의 통신보다 스레드 간의 통신의 비용이 적으므로 작업들 간의 통신의 부담이 줄어들게 된다.
- 스레드 활용의 단점
- 스레드를 활용하면 자원의 효율성이 증가하기도 하지만 스레드 간의 자원 공유는 전역 변수를 이용하므로 동기화 문제에 신경을 써야한다. (각별한 주의 요구됨)
Socket
- 소켓은 1982년 BSD(Berkeley Software Distribution) UNIX 4.1에서 처음 소개되었으며 현재 널리 사용되고 있는 것은 BSD UNIX 4.3에서 개정된 것이다.
- 소프트웨어가 서로 연결하려면 소켓 연결이 필요하다. 소켓은 두 시스템 사이의 네트워크 연결을 나타내는 객체다. 우선적으로 소프트웨어가 연결이 되려면 가장 중요한 것은 두 소프트웨어가 상대방과 통신하는 방법, 즉 상대방에게 비트를 보내는 방법을 알고 있어야만 한다. 소켓 연결은 두 시스템 간의 정보를 연결한다는 것을 의미한다. 그 정보에는 네트워크 주소(IP주소)와 포트번호도 포함되어 있고 이것들을 통해서 소켓을 개설할 수 있다.
- 소켓은 소프트웨어로 작성된 통신 접속점이라고 할 수 있는데 네트웍 응용 프로그램은 소켓을 통하여 통신망으로 데이터를 송수신하게 된다.
- 네트워크 소켓은 컴퓨터 네트워크를 경유하는 프로세스 간 통신의 종착점이다.(위키백과)
- 네트워크 계층을 기준으로 보자면 소켓은 응용프로그램과 트랜스포트 계층 사이에서 역할을 수행한다.
- 소켓은 응용프로그램에서 TCP/IP를 이용하는 창구 역할을 하며 응용 프로그램과 소켓 사이의 인터페이스를 ‘소켓 인터페이스’라고 한다.
- 한 컴퓨터 내에는 보통 한 세트의 TCP/IP가 수행되고 있으며, 네트웍 드라이버는 LAN카드와 같은 네트웍 접속장치(NIU: Network Interface Unit)를 구동하는 소프트웨어를 말한다.
- 포트번호는 TCP/IP가 지원하는 상위 계층의 프로세스를 구분하기 위한 번호이므로 하나의 컴퓨터내에 있는 응용 프로세스들은 반드시 서로 다른 포트번호를 사용하여야 한다.
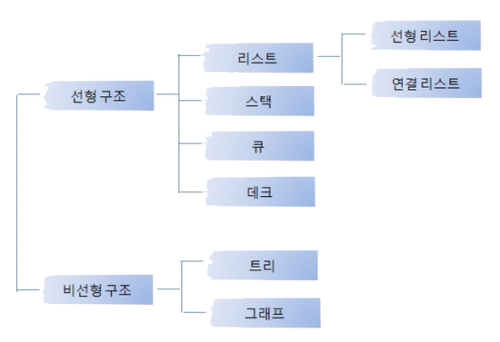
Stack, Queue, Deque
- 선형, 비선형
- 자료구조란 컴퓨터에서 처리할 자료를 효율적으로 관리하고 구조화시키기 위한 것. 즉 자료를 효율적으로 사용하기 위해 자료의 특성에 따라 분류하여 구성하고 저장 및 처리하는 모든 작업을 의미
- 자료구조는 정렬을 하거나 검색을 할 때, 인덱스 처리를 하거나 파일편성을 할 때 이용된다.
- Stack
- 자료의 입력과 출력을 한 곳(방향)으로 제한한 자료구조
- 선입선출(LIFO) 구조, push(), pop()
- 함수의 콜스택에 쓰이고 문자열을 역순으로 출력할 때, 연산자 후위표기법등에 쓰인다.
- 활용 예시: undo나 이전페이지 돌아가는것, 웹브라우저 방문기록, 역순 문자열 만들기
- Queue
- 자료의 입력과 출력이 각각 양 끝에서 이루어진 자료구조
- 후입선출(FiFO)구조 put(), get()
- 일반적인 큐의 단점: 큐에 메모리가 남아 있어도 꽉 차있는 것으로 판단할 수 있음 rear가 배열의 끝에 도달했을 경우 -> 개선된 원형 큐가 나옴
- 원형큐의 단점: 메모리 공간은 잘 활용하나 배열로 구현되어 있기 때문에 큐의 크기가 제한된다. -> 링크드리스트로 큐가 나옴
- 링크드리스트로 구현한 큐는 큐의 크기가 제한이 없고 삽입, 삭제가 편리하다.
- 활용 예시: 우선순위가 같은 작업 예약(인쇄 대기열), 콜센터 고객 대기 시간
- Deque
- 자료의 입력과 출력을 약 쪽 끝에서 가능하게 하는 자료구조
- 스크롤(scroll): 입력이 한쪽 끝으로만 가능하도록 제한한 덱
- 셸프(shelf): 출력이 한쪽 끝으로만 가능하도록 제한한 덱



Docker
- 도커란?
- 도커란 컨테이너 기반의 오픈소스 가상화 플랫폼이다. 다양한 프로그램, 실행환경을 컨테이너로 추상화 하고 동일한 인터페이스를 제공하여 프로그램의 배포 및 관리를 단순하게 해준다.
- 서버운영에 필요한 모든 것을 도커를 활용해 가상환경으로 만들어서 사용할 수 있다.
- 컨테이너(가상머신과의 차이점)
- 컨테이너는 격리된 공간에서 프로세스가 동작하는 기술이다. 가상화 기술의 하나지만 기존 방식과는 차이가 있다.
- 기존의 가상머신은 호스트 OS위에 게스트 OS전체를 가상화하여 사용하는 방식이다. 무겁고 느려서 운영환경에선 사용할 수 없었다.
- 이러한 상황을 개선하기 위해 CPU의 가상화 기술(HVM)을 이용한 KVM(Kernel-based Virtual Machine)과 반가상화(Paravirtualization)방식의 Xen이 등장한다. 이러한 방식은 게스트 OS가 필요하긴 하지만 전체 OS를 가상화하는 방식이 아니였기 때문에 호스트형 가상화 방식에 비해 성능이 향상되었다. 이러한 기술들은 클라우드 서비스에서 가상 컴퓨팅 기술의 기반이 되었다.
- 전가상화든 반가상화든 추가적인 OS를 설치하여 가상화하는 방법은 어쨌든 성능문제가 있었고 이를 개선하기 위해 프로세스를 격리 하는 방식이 등장한다. 리눅스 에서는 이 방식을 리눅스 컨테이너라고 하고 단순히 프로세스를 격리시키기 때문에 가볍고 빠르게 동작한다. CPU나 메로리는 딱 프로세스가 필요한 만큼만 추가로 사용하고 성능적으로도 거의 손실이 없다.
- 이러한 컨테이너라는 개념은 도커가 처음 만든 것은 아니었다.
- 이미지
- 도커에서 가장 중요한 개념은 컨테이너와 함께 이미지라는 개념이다.
- 이미지는 컨테이너 실행에 필요한 파일과 설정값등을 포함하고 있는 것으로 상태값을 가지지 않고 변하지 않습니다. 컨테이너는 이미지를 실행한 상태라고 볼 수 있고 추가되거나 변하는 값은 컨테이너에 저장됩니다. 같은 이미지에서 여러개의 컨테이너를 생성할 수 있고 컨테이너의 상태가 바뀌거나 컨테이너가 삭제되더라도 이미지는 변하지 않고 그대로 남아있다.
- 이미지는 컨테이너를 실행하기 위한 모든 정보를 가지고 있기 때문에 더 이상 의존성 파일을 컴파일하고 이것저것 설치할 필요가 없습니다. 이제 새로운 서버가 추가되면 미리 만들어 놓은 이미지를 다운받고 컨테이너를 생성만 하면 됩니다. 한 서버에 여러개의 컨테이너를 실행할 수 있고, 수십, 수백, 수천대의 서버도 문제없습니다.
IaaS, PaaS, SaaS
- 최초 클라우드 서비스는 지메일이나 드롭박스, 네이버 클라우드처럼 소프트웨어를 웹에서 쓸 수 있는 SaaS가 대부분이었다. 그러다가 서버와 스토리지, 네트워크 같은 컴퓨팅 인프라 장비를 빌려주는 IaaS, 플랫폼을 빌려주는 PaaS로 늘어났다. 클라우드 서비스는 어떤 자원을 제공하느냐에 따라 이처럼 크게 3가지로 나뉜다.

- SaaS가 이미 만들어진 레고 모형, IaaS가 레고 공장이라면, PaaS는 레고 블럭이라 할 수 있다.
- SaaS : SaaS는 클라우드 환경에서 운영되는 애플리케이션 서비스를 말한다. 모든 서비스가 클라우드에서 이뤄진다. 소프트웨어를 구입해서 PC에 설치하지 않아도 웹에서 소프트웨어를 빌려쓸 수 있다. SaaS는 필요할 때 원하는 비용만 내면 어디서든 곧바로 슬 수 있다는 장범이 있다. PC나 기업 서버에 소프트웨어를 설치할 필요가 없다. 소프트웨어 설치를 위해 비용과 시간을 들이지 않아도 된다. SaaS는 중앙에서 해당 소프트웨어를 관리하기 때문에 사용자가 일일이 업그레이드나 패치 작업을 할 필요도 없다.
- PaaS : PaaS는 소프트웨어 서비스를 개발할 때 필요한 플랫폼을 제공하는 서비스다. 사용자는 PaaS에서 필요한 서비스를 선택해 애플리케이션을 개발하면 된다. PaaS 운영 업체는 개발자가 소프트웨어를 개발할 때 필요한 API를 제공해 개발자가 좀 더 편하게 앱을 개발할 수 있게 돕는다. 일종의 레고 블럭같은 서비스다. 개발자가 개발을 하는 데 필요한 도구와 환경을 사용하고, 사용한 만큼만 비용을 내기 때문에 개발자로선 비용 부담을 덜 수 있다. 단, 플랫폼 기반으로 애플리케이션을 개발하기 때문에 특정 플랫폼에 종속될 수 있다는 단점이 있다. A 서비스 업체의 PaaS에서 앱을 개발하고 이 작업을 이어서 B 외사의 PaaS에서 하기가 쉽지 않다는 뜻이다. 다양한 플랫폼에서 작업하려면 이에 맞게 앱을 수정하는 과정이 필요하다. (컴퓨터 인프라를 클라우드로 제공하는 것에 더하여 애플리케이션을 가동하기 위한 플랫폼을 제공하는 것)
- IaaS: 데이터센터를 구축하는 대신 클라우드를 이용해 필요한 컴퓨팅 인프라를 사용하는 걸 IaaS라고 부른다. 이용자는 서버나 스토리지를 구입,운영하는 비용을 줄일 수 있다. IaaS는 인터넷을 통해 서버와 스토리지 등 데이터센터 자원을 빌려 쓸 수 있는 서비스를 일컫는다. 이용자는 직접 데이터센터를 구축할 필요 없이 클라우드 환경에서 필요한 인프라를 꺼내 스면 된다. 이렇게 빌려온 인프라에서 사용자는 운영체제를 설치하고, 애플리케이션 등을 설치한 다음 원하는 서비스를 운영할 수 있다. IaaS는 가상 서버, 데이터 스토리지 같은 기존 데이터센터가 제공하는 서비스를 제공한다. 사용자는 이런 서비스를 조합해 애플리케이션을 실행하거나 운영할 수 있다. 게다가 물리적으로 만들어진 환경이 아니기 때문에 사용하지 않을 때 시스템을 해체하는 것도 손쉽다. (컴퓨터 인프라를 클라우드로 제공하는 것)
Database Index
- 인덱스는 데이터베이스 분야에 있어서 테이블에 대한 동작의 속도를 높여주는 자료 구조를 일컫는다. 인덱스는 테이블 내의 1개의 컬럼, 혹은 여러개의 컬럼을 이용하여 생성될 수 있다. 고속의 검색 동작뿐만 아니라 레코드 접근과 관련 효율적인 순서 매김 동작에 대한 기초를 제공한다. 인덱스를 저장하는 데 필요한 디스크 공간은 보통 테이블을 저장하는 데 필요한 디스크 공간보다 작다. (왜냐하면 보통 인덱스는 키-필드만 갖고 있고, 테이블의 다른 세부 항목들은 갖고 있지 않기 때문이다.) 관계형 데이터베이스에서는 인덱스는 테이블 부분에 대한 하나의 사본이다. (위키백과)
- INDEX란 RDBMS에서 검색속도를 높이기 위해 사용하는 하나의 기술. INDEX는 색인이다. 해당 Table의 컬럼을 색인화(따로 파일로 저장)하여 검색시 해당 Table의 레코드를 모두 스캔하는게 아니라 색인화 되어있는 INDEX파일을 검색하여 검색속도를 빠르게 한다. 이런 INDEX는 Tree구조로 색인화 한다. RDBMS에서 사용하는 INDEX는 Balance Search Tree를 사용한다. 실제로 RDBMS에서 사용되는 B-Tree는 B-Tree에서 파생된 B+Tree를 사용한다고 한다. (참고로 Oracle이나 MSSQL에서는 여러 종류의 Tree를 선택하여 사용가능하다.)
- INDEX의 원리 INDEX를 해당 컬럼에 주게 되면 초기 Table생성시 만들어진 MYD, MYI, FRM 3개의 파일 중에서 MYI에 해당 컬럼을 색인화 하여 저장한다. 물론 INDEX를 사용하지 않을 시에는 MYI파일은 비어 있다. 그래서 INDEX를 해당컬럼에 만들게 되면 해당컬럼을 따로 인덱싱하여 MYI파일에 입력한다. 그래서 사용자가 SELECT쿼리로 INDEX가 사용하는 쿼리를 사용시 해당 Table을 검색하는 것이 아니라 빠른 Tree로 정리해둔 MYI파일의 내용을 검색한다. 만약 INDEX를 사용하지 않은 SELECT쿼리라면 해당 Table을 모두 스캔하여 검색한다. 이는 책의 뒷부분에 찾아보기와 같은 의미로 정리해둔 단어중에서 원하는 단어를 찾아서 페이지수를 보고 쉽게 찾을 수 있는 개념과 같다. 만약 이 찾아보기가 없다면 처음부터 끝까지 모든 페이지를 보고 찾아야 할 것이다.
- INDEX의 장점
- 키 값을 기초로 하여 테이블에서 검색과 정렬 속도를 향상시킨다.
- 쿼리나 보고서에서 그룹화 작업의 속도를 향상시킨다.
- 인덱스를 사용하면 테이블 행의 공유성을 강화시킬 수 있다.
- INDEX의 단점
- 인덱스를 만들면
.mdb파일의 크기가 커진다. - 여러 사용자가 사용하는 응용프로그램에서의 여러 사용자가 한 페이지를 동시에 수정할 수 있는 병행성이 줄어든다.
- 인덱스 된 필드에서 데이터를 업데이트하거나, 레코드를 추가 또는 삭제할 때 성능이 떨어진다.
- 인덱스가 데이터베이스 공간을 차지해 추가적인 공간이 필요해진다.(DB의 10퍼센트 내외의 공간이 추가로 필요)
- 데이터 변경 작업이 자주 일어날 경우에 인덱스를 재작성해야 할 필요가 있기에 성능에 영향을 끼칠 수 있다.
- 인덱스를 만들면
- DBMS
- Data Base Management System
- 데이터베이스 관리 시스템(DBMS)은 다수의 사용자들이 데이터베이스 내의 데이터를 접근할 수 있도록 해주는 소프트웨어 도구의 집합이다. DBMS는 사용자 또는 다른 프로그램의 요구를 처리하고 적절히 응답하여 데이터를 사용할 수 있도록 해준다.
- Balance Search Tree
- 트리구조의 높이를 작게 만들어 효율적으로 탐색할 수 있게끔 만든 구조
- MYD, MYI, FRM
- MYD - Index정보가 들어가 있는 파일
- MYI - 실제 데이터가 들어가 있는 파일
- FRM - 테이블 구조가 저장되어 있는 파일
- DDL, DML, DCL
- DDL - 데이터베이스의 스키마 객체를 생성, 변경, 제거하거나 권한의 부여나 박탈, 주석, 자료의 버림 등을 수행하는 문장의 집단을 의미한다.
- DML - 스키마 객체의 데이터를 입력, 수정, 조회, 삭제 하거나 테이블에 잠금을 설정하거나 SQL문의 처리에 대한 절차에 대한 정보를 얻거나 PL/-SQL 모듈을 호출하는 작업의 집단이다.
- DCL - 데이터를 제어하는 언어, 데이터의 보안, 무결성, 회복, 병행 수행제어 등을 정의하는데 사용
OSI 모델
-
각 단계별 설명
-
계층 내용 7 계층 응용계층 사용자에게 네트워크 서비스를 제공한다. 6 계층 표현계층 데이터의 형식을 결정한다. 5 계층 세션계층 데이터의 송수신의 순서 등을 관리한다. 4 계층 전송계층 신뢰성이 높은(에러가 적은)전송을 시행한다. 3 계층 네트워크계층 전송 규칙과 수신처를 결정한다. 2 계층 데이터링크계층 인접기기 사이의 데이터 전송을 제어한다. 1 계층 물리계층 전기,기계적인 부분의 전송을 시행한다.
객체지향개발(OOP) 4가지 특성
- 추상화
- 공통의 속성이나 기능을 묶어 이름을 붙이는 것
- OOP 에서 클래스를 정의하는 것을 추상화라고 할 수 있다.
- 캡슐화
- 변수와 함수를 하나로 묶어서 외부에서의 접근을 막고, 함수를 통해서만 접근 가능하도록 하는 것
- 객체가 맡은 역할을 수행하기 위한 데이터를 하나로 묶는다 (은닉화)
- 상속
- 상위 개념의 특징을 하위 개념이 물려 받는 것
- 다형성
- 부모 클래스로부터 물려받은 가상 함수를 자식 클래스 내에서 오버라이딩 하여 사용하는 것
- 다형성의 쉬운 예제는 Java의 오버로딩이다. 오버로딩은 같은 의미지만 매개변수의 데이터타입이 무엇이냐에 따라서 다른 메소드가 호출되는 방식이다. 참고 (참고로 파이썬은 오버로딩을 허용하지 않는다.)